
SoundHound AI Stock Rises After Price-Target Increase Analysis
“`html SoundHound AI Stock Rises After Price-Target Increase Analysis In a rapidly evolving technological landscape, Artificial Intelligence (AI) continues to


Several years ago, Amazon needed to improve the way it routed customer service calls, so it looked to machine learning for help.
The original Amazon call center routing system worked something like this. A customer would call in and was greeted by a menu: “Press 1 for Returns. Press 2 for Kindle. Press 3 for…,” and so on. The customer would then make a selection and be sent to an agent who would be trained in the specific skills to help the customer.
During the problem formulation phase of the pipeline, Amazon determined that the current routing system was problematic. Amazon sells many types of products, so the list of things a customer might be calling about is nearly endless. If we didn’t play the right option to a customer calling in, the customer might be sent to a generalist or even to the wrong specialist, who then had to figure out what the customer needed before finally sending them to the agent with the right skills.
For some businesses, this might not be a problem. For Amazon, dealing with hundreds of millions of customer calls a year, it was inefficient. It cost a lot of money, wasted a lot of time, and worst of all, it was not a good way to get our customers the help they needed.

The business problem was focused around figuring out how to route customers to agents with the right skills and, therefore, reduce call transfers.
To solve this problem, we needed to predict which skill would solve a customer call.
When converted to a machine learning problem, this became identifying patterns in customer data that we could use to predict accurate customer routing. Based on the wording of this ML problem, it was clear that we were dealing with a multiclass classification problem.
Because we wanted to base our predictions on past data from customer service calls, we were dealing with supervised learning. We eventually would train our model on historical customer data that included the correct labels or customer agent skills. Then, the model could make its own predictions on similar data moving forward. For example, predicting that a customer call needed a Kindle skill.
The data we needed came from answering questions like, “What were the customer’s recent orders?” “Did the customer own a Kindle?” “Are they Prime members?” The answers to these questions became our features.
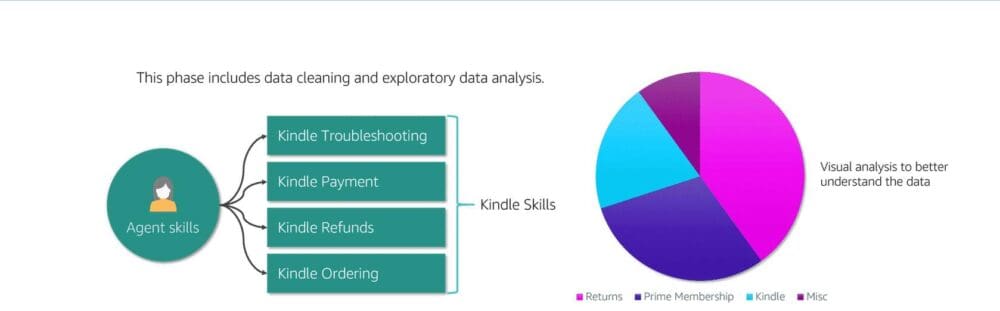
We then moved on to the data preparation or preprocessing phase. This phase includes data cleaning and exploratory data analysis.
A lot was done at this point, but one example of data analysis was to think critically about the labels we were using. We asked ourselves a few questions, “Are there any labels we want to exclude from the model for some business reason?” “Are there any labels that are not entirely accurate?” “Are any labels similar enough to be combined?” Finding answers to these questions by exploring the data would help cut down on the number of features being used and simplify our model.
An example of what we found in this type of analysis was combining labels that represented multiple Kindle skills into one overarching Kindle skill label. That way, every customer who had a problem with a Kindle was routed to an agent trained in all Kindle issues.
Data visualization was the next step, where we did a number of things, including a programmatic analysis, to give us a quick sense of feature and label summaries. This helped us better understand the data we were working with. For example, we could have learned that 40 percent of calls were related to returns, 30 percent were related to Prime memberships, 30 percent were related to Kindle, and so on.
A big part of preparing for the training process is to first split your data to ensure a proper division between your training and evaluation efforts.
The fundamental goal of ML is to generalize beyond the data instances used to train models. You want to evaluate your model to estimate the quality of its predictions for the data that the model has not been trained on. However, as is the case in supervised learning, because future instances have unknown target values and you cannot check the accuracy of your predictions for future instances now, you need to use some of the data that you already know the answer for as a proxy for future data.
Evaluating the model with the same data that was used for training is not useful, because it rewards models that can remember the training data, as opposed to generalizing from it.
A common strategy is to split all available labeled data into training, validation, and testing subsets, usually with a ratio of 80 percent,10 percent, and 10percent. (Another common ratio is 70 percent,15 percent, and 15percent.)

After we were happy with how the model interacted with unseen test data, we deployed the model into production and monitored it to make sure that our business problem was indeed being addressed.
Our problem was predicated on the assumption that the ability to more accurately predict skills would reduce the number of transfers a customer experienced. That was put to the test after we deployed, and the number of transfers did decrease, which resulted in a much better customer experience.

After running a training job, we evaluated our model and began a process of iterative tweaks to the model and our data.
For instance, we performed hyperparameter optimization. We tweaked the learning parameters to control how fast or slow our model was learning.
Learning too fast means that the algorithm will never reach an optimum value. Learning too slow means that the algorithm takes too long and might never converge to the optimum in the given number of steps.
We then moved on to feature engineering. We had features that answered questions like, “What was a customer’s most recent order?” “What was the time of a customer’s most recent order?” “Does the customer own a kindle?” When we feed these features into the model training algorithm, it can only learn from exactly what we show it.
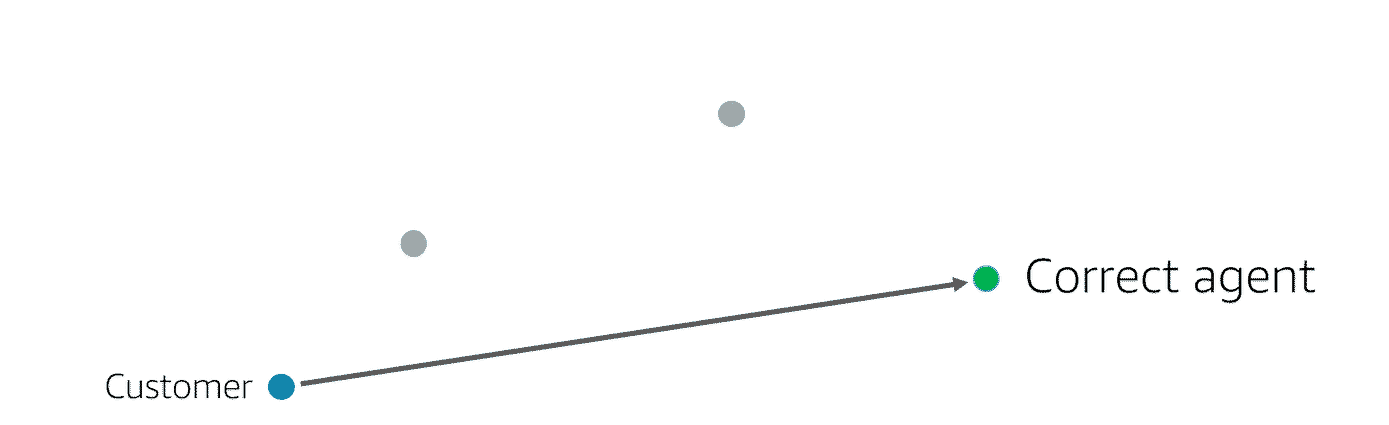
We then deployed the model. It now helps customers get directed to the correct agent the first time.
“`html SoundHound AI Stock Rises After Price-Target Increase Analysis In a rapidly evolving technological landscape, Artificial Intelligence (AI) continues to

“`html Explore Google’s Innovative Generative AI Video Model Now Available In the ever-evolving world of technology, Google has once again
